AI Incorrectly Cites Sources In 60% of Searches, Reinforces Accuracy Concerns
Concerns about the accuracy of information generated by AI models has now been reinforced by a new study which reveals that 60% of AI responses to research inquiries are inaccurate.
The study included famous and popular models like ChatGPT and Grok. That AI models tend to respond authoritatively when they dont know the correct answer, rather than acknowledging that they don't know may be characteristic of tech egos, but is not helpful for instilling confidence in either corporate customers or customers. JL
Benj Edwards reports in ars technica:
A new study finds serious accuracy issues with generative AI models used for news searches. The AI models incorrectly cited sources in more than 60% of these queries, raising significant concerns about their reliability. The study highlighted a trend among these AI models: rather than declining to respond when they lacked reliable information, the models frequently provided plausible-sounding but incorrect or speculative answers—known technically asconfabulations. 1 in 4 Americans now use AI models as alternatives to traditional search engines. Given that these models struggle significantly when specifically asked to attribute news sources, this raises broader questions about their general reliability.
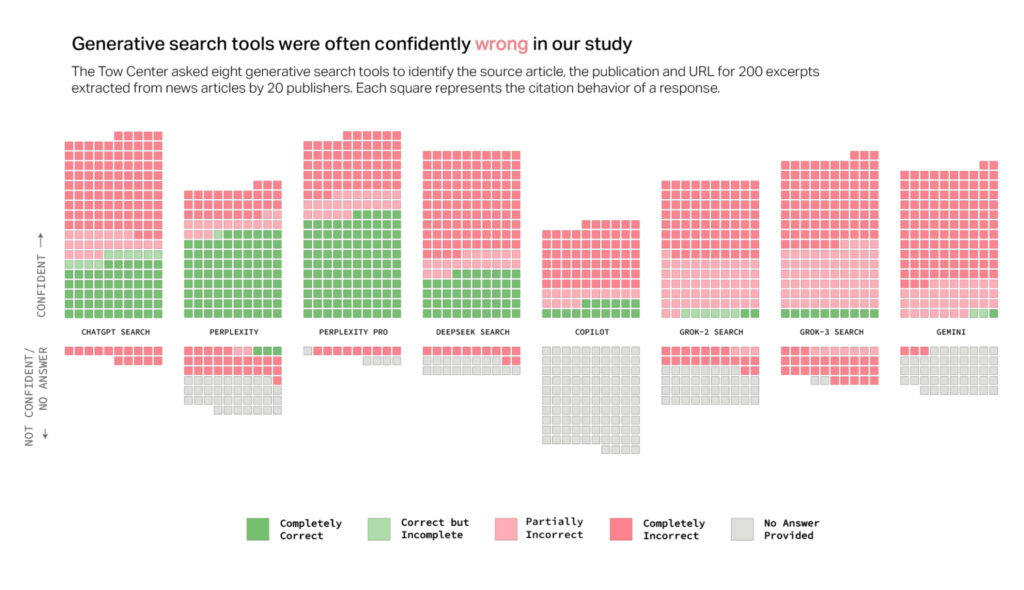
A new study from Columbia Journalism Review's Tow Center for Digital Journalism finds serious accuracy issues with generative AI models used for news searches. The researchers tested eight AI-driven search tools by providing direct excerpts from real news articles and asking the models to identify each article's original headline, publisher, publication date, and URL. They discovered that the AI models incorrectly cited sources in more than 60 percent of these queries, raising significant concerns about their reliability in correctly attributing news content.
Researchers Klaudia Jaźwińska and Aisvarya Chandrasekar noted in their report that roughly 1 in 4 Americans now use AI models as alternatives to traditional search engines. Given that these models struggle significantly when specifically asked to attribute news sources, this raises broader questions about their general reliability.
Citation error rates varied notably among the tested platforms. Perplexity provided incorrect information in 37 percent of the queries tested, whereas ChatGPT Search incorrectly identified 67 percent (134 out of 200) of articles queried. Grok 3 demonstrated the highest error rate, at 94 percent. In total, researchers ran 1,600 queries across the eight different generative search tools.
A graph from CJR shows "confidently wrong" search results. Credit: CJR
The study highlighted a common trend among these AI models: rather than declining to respond when they lacked reliable information, the models frequently provided plausible-sounding but incorrect or speculative answers—known technically as confabulations. The researchers emphasized that this behavior was consistent across all tested models, not limited to just one tool.
Surprisingly, premium paid versions of these AI search tools fared even worse in certain respects. Perplexity Pro ($20/month) and Grok 3's premium service ($40/month) confidently delivered incorrect responses more often than their free counterparts. Though these premium models correctly answered a higher number of prompts, their reluctance to decline uncertain responses drove higher overall error rates.
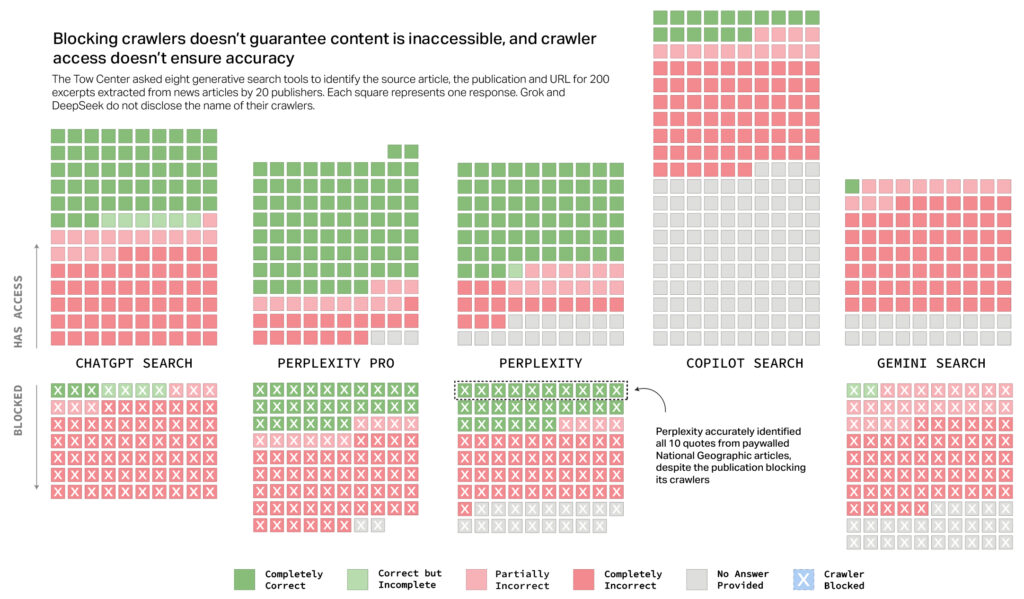
The CJR researchers also uncovered evidence suggesting some AI tools ignored Robot Exclusion Protocol settings—a widely accepted voluntary standard publishers use to request that web crawlers avoid accessing specific content. For example, Perplexity’s free version correctly identified all 10 excerpts from paywalled National Geographic content, despite National Geographic explicitly disallowing Perplexity’s web crawlers. Even when these AI search tools cited sources, they often directed users to syndicated versions of content on platforms like Yahoo News rather than original publisher sites. This occurred even in cases where publishers had formal licensing agreements with AI companies.
URL fabrication emerged as another significant problem. More than half of citations from Google's Gemini and Grok 3 led users to fabricated or broken URLs resulting in error pages. Of 200 citations tested from Grok 3, 154 resulted in broken links.
These issues create significant tension for publishers, which face difficult choices. Blocking AI crawlers might lead to loss of attribution entirely, while permitting them allows widespread reuse without driving traffic back to publishers' own websites.
A graph from CJR showing that blocking crawlers doesn't mean that AI search providers honor the request. Credit: CJR
Mark Howard, chief operating officer at Time magazine, expressed concern to CJR about ensuring transparency and control over how Time's content appears via AI-generated searches. Despite these issues, Howard sees room for improvement in future iterations, stating, "Today is the worst that the product will ever be," citing substantial investments and engineering efforts aimed at improving these tools.
However, Howard also did some user shaming, suggesting it's the user's fault if they aren't skeptical of free AI tools’ accuracy: "If anybody as a consumer is right now believing that any of these free products are going to be 100 percent accurate, then shame on them."
OpenAI and Microsoft provided statements to CJR acknowledging receipt of the findings but did not directly address the specific issues. OpenAI noted its promise to support publishers by driving traffic through summaries, quotes, clear links, and attribution. Microsoft stated it adheres to Robot Exclusion Protocols and publisher directives.
The latest report builds on previous findings published by the Tow Center in November 2024, which identified similar accuracy problems in how ChatGPT handled news-related content. For more detail on the fairly exhaustive report, check out Columbia Journalism Review's website.
As a Partner and Co-Founder of Predictiv and PredictivAsia, Jon specializes in management performance and organizational effectiveness for both domestic and international clients. He is an editor and author whose works include Invisible Advantage: How Intangilbles are Driving Business Performance. Learn more...




















0 comments:
Post a Comment