How Information Overload Is Helping Social Media Spread Fake Covid News
The proliferation of media and the information overload it has produced cause humans to use cognitive shortcuts to process the overwhelming volume.
This results in an over-reliance on preconceptions and biases, which are inflamed by social media programmed to elicit emotions that drive engagement. JL
Filippo Menczer and Thomas Hills report in Scientific American:
The proliferation of online information - blogs,
videos, tweets and memes - has become so
cheap and easy that the information marketplace is inundated. Unable to
process all this material, we let our cognitive biases decide what we
should pay attention to. These mental shortcuts influence which
information we search for, comprehend, remember and repeat to a harmful
extent. Search engines inflame suspicions, and
social media connect like-minded people, feeding fears. Automated social media accounts enable malevolent actors to take
advantage of vulnerabilities.
Consider Andy, who is worried about contracting COVID-19. Unable to read all the articles he sees on it, he relies on trusted friends for tips. When one opines on Facebook that pandemic fears are overblown, Andy dismisses the idea at first. But then the hotel where he works closes its doors, and with his job at risk, Andy starts wondering how serious the threat from the new virus really is. No one he knows has died, after all. A colleague posts an article about the COVID “scare” having been created by Big Pharma in collusion with corrupt politicians, which jibes with Andy's distrust of government. His Web search quickly takes him to articles claiming that COVID-19 is no worse than the flu. Andy joins an online group of people who have been or fear being laid off and soon finds himself asking, like many of them, “What pandemic?” When he learns that several of his new friends are planning to attend a rally demanding an end to lockdowns, he decides to join them. Almost no one at the massive protest, including him, wears a mask. When his sister asks about the rally, Andy shares the conviction that has now become part of his identity: COVID is a hoax.
This example illustrates a minefield of cognitive biases. We prefer information from people we trust, our in-group. We pay attention to and are more likely to share information about risks—for Andy, the risk of losing his job. We search for and remember things that fit well with what we already know and understand. These biases are products of our evolutionary past, and for tens of thousands of years, they served us well. People who behaved in accordance with them—for example, by staying away from the overgrown pond bank where someone said there was a viper—were more likely to survive than those who did not.
Modern technologies are amplifying these biases in harmful ways, however. Search engines direct Andy to sites that inflame his suspicions, and social media connects him with like-minded people, feeding his fears. Making matters worse, bots—automated social media accounts that impersonate humans—enable misguided or malevolent actors to take advantage of his vulnerabilities.
Compounding the problem is the proliferation of online information. Viewing and producing blogs, videos, tweets and other units of information called memes has become so cheap and easy that the information marketplace is inundated. Unable to process all this material, we let our cognitive biases decide what we should pay attention to. These mental shortcuts influence which information we search for, comprehend, remember and repeat to a harmful extent.
The need to understand these cognitive vulnerabilities and how algorithms use or manipulate them has become urgent. At the University of Warwick in England and at Indiana University Bloomington's Observatory on Social Media (OSoMe, pronounced “awesome”), our teams are using cognitive experiments, simulations, data mining and artificial intelligence to comprehend the cognitive vulnerabilities of social media users. Insights from psychological studies on the evolution of information conducted at Warwick inform the computer models developed at Indiana, and vice versa. We are also developing analytical and machine-learning aids to fight social media manipulation. Some of these tools are already being used by journalists, civil-society organizations and individuals to detect inauthentic actors, map the spread of false narratives and foster news literacy.
INFORMATION OVERLOAD
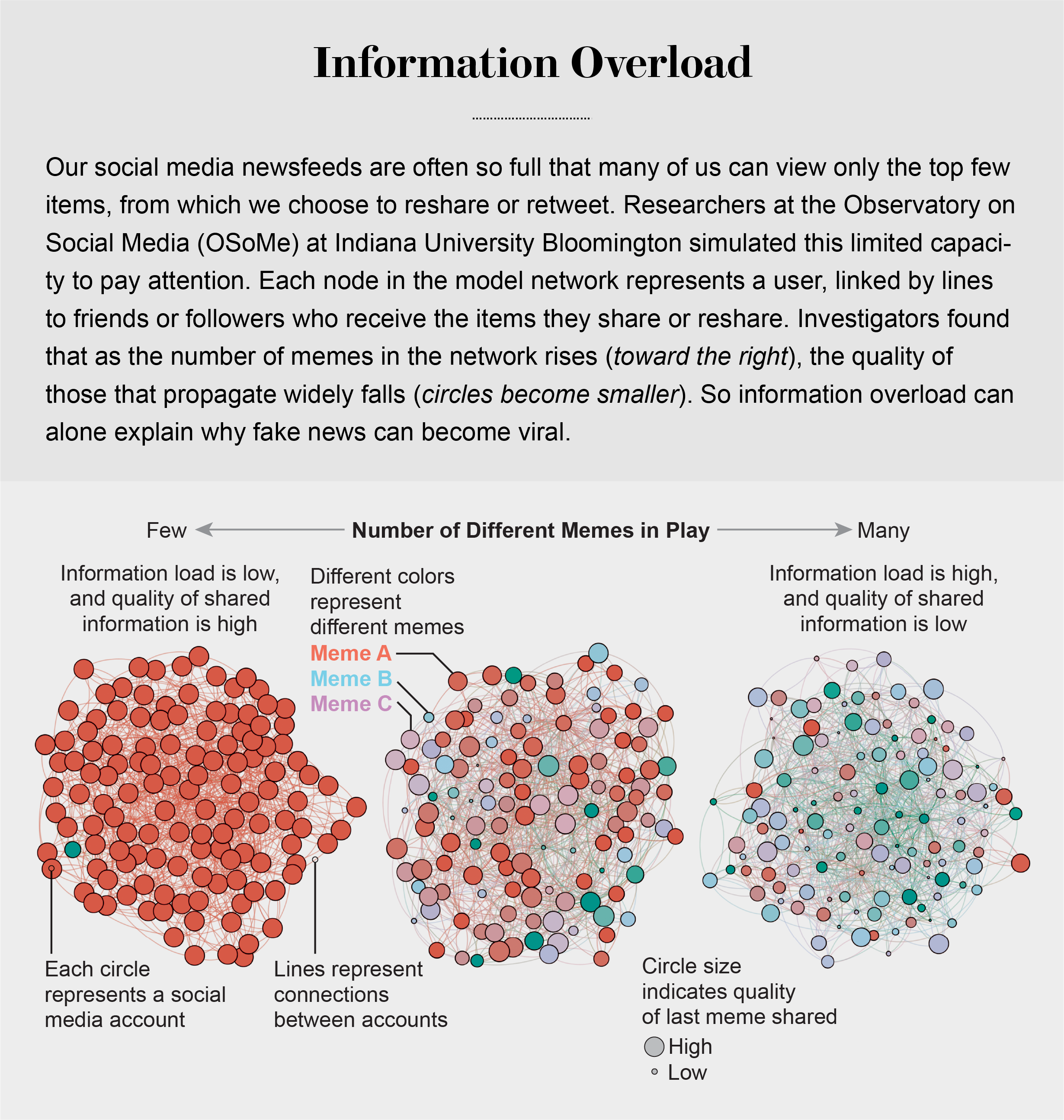
The glut of information has generated intense competition for people's attention. As Nobel Prize–winning economist and psychologist Herbert A. Simon noted, “What information consumes is rather obvious: it consumes the attention of its recipients.” One of the first consequences of the so-called attention economy is the loss of high-quality information. The OSoMe team demonstrated this result with a set of simple simulations. It represented users of social media such as Andy, called agents, as nodes in a network of online acquaintances. At each time step in the simulation, an agent may either create a meme or reshare one that he or she sees in a news feed. To mimic limited attention, agents are allowed to view only a certain number of items near the top of their news feeds.
Running this simulation over many time steps, Lilian Weng of OSoMefoundthat as agents' attention became increasingly limited, the propagation of memes came to reflect the power-law distribution of actual social media: the probability that a meme would be shared a given number of times was roughly an inverse power of that number. For example, the likelihood of a meme being shared three times was approximately nine times less than that of its being shared once.
Credit: “Limited individual attention and online virality of low-quality information,” By Xiaoyan Qiu et al., inNature Human Behaviour, Vol. 1, June 2017
This winner-take-all popularity pattern of memes, in which most are barely noticed while a few spread widely, could not be explained by some of them being more catchy or somehow more valuable: the memes in this simulated world had no intrinsic quality. Virality resulted purely from the statistical consequences of information proliferation in a social network of agents with limited attention. Even when agents preferentially shared memes of higher quality, researcher Xiaoyan Qiu, then at OSoMe, observed little improvement in the overall quality of those shared the most.Our models revealedthat even when we want to see and share high-quality information, our inability to view everything in our news feeds inevitably leads us to share things that are partly or completely untrue.
Cognitive biases greatly worsen the problem. In a set of groundbreaking studies in 1932, psychologist Frederic Bartlett told volunteers a Native American legend about a young man who hears war cries and, pursuing them, enters a dreamlike battle that eventually leads to his real death. Bartlett asked the volunteers, who were non-Native, to recall the rather confusing story at increasing intervals, from minutes to years later. He found that as time passed, the rememberers tended to distort the tale's culturally unfamiliar parts such that they were either lost to memory or transformed into more familiar things. We now know that our minds do this all the time: they adjust our understanding of new information so that it fits in with what we already know. One consequence of this so-called confirmation bias is that people often seek out, recall and understand information that best confirms what they already believe.
This tendency is extremely difficult to correct. Experiments consistently show that even when people encounter balanced information containing views from differing perspectives, they tend to find supporting evidence for what they already believe. And when people with divergent beliefs about emotionally charged issues such as climate change are shown the same information on these topics, they become even more committed to their original positions.
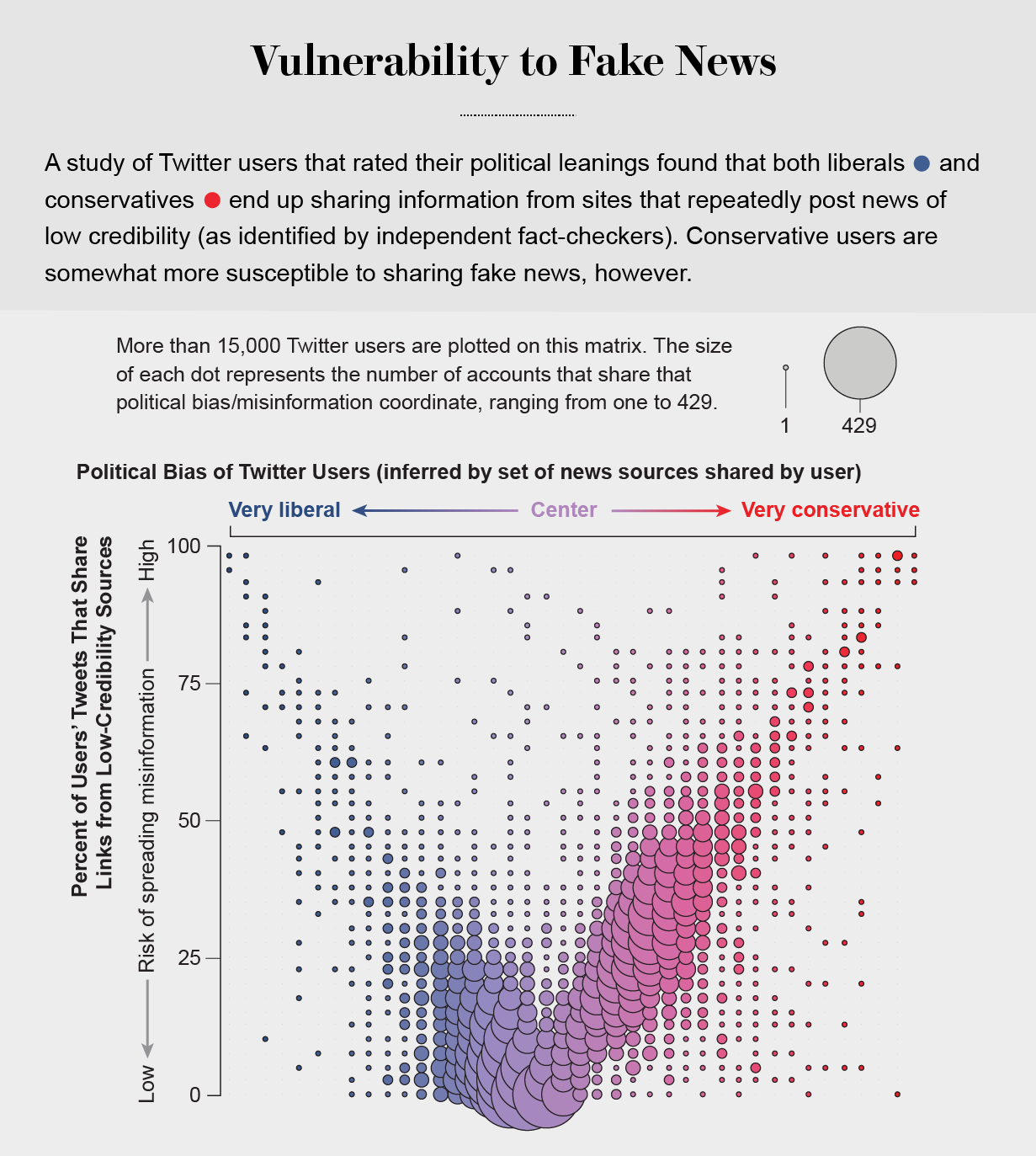
Making matters worse, search engines and social media platforms provide personalized recommendations based on the vast amounts of data they have about users' past preferences. They prioritize information in our feeds that we are most likely to agree with—no matter how fringe—and shield us from information that might change our minds. This makes us easy targets for polarization. Nir Grinberg and his co-workers at Northeastern University recently showed that conservatives in the U.S. are more receptive to misinformation. But our own analysis of consumption of low-quality information on Twitter shows that the vulnerability applies to both sides of the political spectrum, and no one can fully avoid it. Even our ability to detect online manipulation is affected by our political bias, thoughnot symmetrically: Republican users are more likely to mistake bots promoting conservative ideas for humans, whereas Democrats are more likely to mistake conservative human users for bots.
Credit: Filippo Menczer
SOCIAL HERDING
In New York City in August 2019, people began running away from what sounded like gunshots. Others followed, some shouting, “Shooter!” Only later did they learn that the blasts came from a backfiring motorcycle. In such a situation, it may pay to run first and ask questions later. In the absence of clear signals, our brains use information about the crowd to infer appropriate actions, similar to the behavior of schooling fish and flocking birds.
Such social conformity is pervasive. In a fascinating 2006 study involving 14,000 Web-based volunteers, Matthew Salganik, then at Columbia University, and his colleagues found that when people can see what music others are downloading, they end up downloading similar songs. Moreover, when people were isolated into “social” groups, in which they could see the preferences of others in their circle but had no information about outsiders, the choices of individual groups rapidly diverged. But the preferences of “nonsocial” groups, where no one knew about others' choices, stayed relatively stable. In other words, social groups create a pressure toward conformity so powerful that it can overcome individual preferences, and by amplifying random early differences, it can cause segregated groups to diverge to extremes.
Social media follows a similar dynamic. We confuse popularity with quality and end up copying the behavior we observe. Experiments on Twitter by Bjarke Mønsted and his colleagues at the Technical University of Denmark and the University of Southern California indicate that information is transmitted via “complex contagion”: when we are repeatedly exposed to an idea, typically from many sources, we are more likely to adopt and reshare it. This social bias is further amplified by what psychologists call the “mere exposure” effect: when people are repeatedly exposed to the same stimuli, such as certain faces, they grow to like those stimuli more than those they have encountered less often.
Credit: Jen Christiansen; Source: Dimitar Nikolov and Filippo Menczer (data)
Such biases translate into an irresistible urge to pay attention to information that is going viral—if everybody else is talking about it, it must be important. In addition to showing us items that conform with our views, social media platforms such as Facebook, Twitter, YouTube and Instagram place popular content at the top of our screens and show us how many people have liked and shared something. Few of us realize that these cues do not provide independent assessments of quality.
In fact, programmers who design the algorithms for ranking memes on social media assume that the “wisdom of crowds” will quickly identify high-quality items; they use popularity as a proxy for quality. Ouranalysis of vast amounts of anonymous data about clicksshows that all platforms—social media, search engines and news sites—preferentially serve up information from a narrow subset of popular sources.
To understand why, we modeled how they combine signals for quality and popularity in their rankings. In this model, agents with limited attention—those who see only a given number of items at the top of their news feeds—are also more likely to click on memes ranked higher by the platform. Each item has intrinsic quality, as well as a level of popularity determined by how many times it has been clicked on. Another variable tracks the extent to which the ranking relies on popularity rather than quality.Simulations of this model revealthat such algorithmic bias typically suppresses the quality of memes even in the absence of human bias. Even when we want to share the best information, the algorithms end up misleading us.
ECHO CHAMBERS
Most of us do not believe we follow the herd. But our confirmation bias leads us to follow others who are like us, a dynamic that is sometimes referred to as homophily—a tendency for like-minded people to connect with one another. Social media amplifies homophily by allowing users to alter their social network structures through following, unfriending, and so on. The result is that people become segregated into large, dense and increasingly misinformed communities commonly described as echo chambers.
At OSoMe, we explored the emergence of online echo chambers through another simulation,EchoDemo. In this model, each agent has a political opinion represented by a number ranging from −1 (say, liberal) to +1 (conservative). These inclinations are reflected in agents' posts. Agents are also influenced by the opinions they see in their news feeds, and they can unfollow users with dissimilar opinions. Starting with random initial networks and opinions, we found that the combination of social influence and unfollowinggreatly acceleratesthe formation of polarized and segregated communities.
Indeed, the political echo chambers on Twitter are so extreme that individual users' political leanings can be predicted withhigh accuracy: you have the same opinions as the majority of your connections. This chambered structureefficiently spreads informationwithin a community while insulating that community from other groups. In 2014 our research group was targeted by a disinformation campaign claiming that we were part of a politically motivated effort to suppress free speech. This false charge spread virally mostly in the conservative echo chamber, whereas debunking articles by fact-checkers were found mainly in the liberal community. Sadly, such segregation of fake news items from their fact-check reports is the norm.
Social media can also increase our negativity. In a recent laboratory study, Robert Jagiello, also at Warwick,foundthat socially shared information not only bolsters our biases but also becomes more resilient to correction. He investigated how information is passed from person to person in a so-called social diffusion chain. In the experiment, the first person in the chain read a set of articles about either nuclear power or food additives. The articles were designed to be balanced, containing as much positive information (for example, about less carbon pollution or longer-lasting food) as negative information (such as risk of meltdown or possible harm to health).
The first person in the social diffusion chain told the next person about the articles, the second told the third, and so on. We observed an overall increase in the amount of negative information as it passed along the chain—known as the social amplification of risk. Moreover, work by Danielle J. Navarro and her colleagues at the University of New South Wales in Australia found that information in social diffusion chains is most susceptible to distortion by individuals with the most extreme biases.
Even worse, social diffusion also makes negative information more “sticky.” When Jagiello subsequently exposed people in the social diffusion chains to the original, balanced information—that is, the news that the first person in the chain had seen—the balanced information did little to reduce individuals' negative attitudes. The information that had passed through people not only had become more negative but also was more resistant to updating.
ADVERTISEMENT
A2015 studyby OSoMe researchers Emilio Ferrara and Zeyao Yang analyzed empirical data about such “emotional contagion” on Twitter and found that people overexposed to negative content tend to then share negative posts, whereas those overexposed to positive content tend to share more positive posts. Because negative content spreads faster than positive content, it is easy to manipulate emotions by creating narratives that trigger negative responses such as fear and anxiety. Ferrara, now at the University of Southern California, and his colleagues at the Bruno Kessler Foundation in Italy have shown that during Spain's 2017 referendum on Catalan independence, social bots were leveraged to retweetviolent and inflammatory narratives, increasing their exposure and exacerbating social conflict.
RISE OF THE BOTS
Information quality is further impaired by social bots, which can exploit all our cognitive loopholes. Bots are easy to create. Social media platforms provide so-called application programming interfaces that make it fairly trivial for a single actor to set up and control thousands of bots. But amplifying a message, even with just a few early upvotes by bots on social media platforms such as Reddit, can have ahuge impacton the subsequent popularity of a post.
At OSoMe, we have developed machine-learning algorithms to detect social bots. One of these,Botometer, is a public tool that extracts 1,200 features from a given Twitter account to characterize its profile, friends, social network structure, temporal activity patterns, language and other features. The program compares these characteristics with those of tens of thousands of previously identified bots to give the Twitter account a score for its likely use of automation.
In 2017 weestimatedthat up to 15 percent of active Twitter accounts were bots—and that they hadplayed a key rolein the spread of misinformation during the 2016 U.S. election period. Within seconds of a fake news article being posted—such as one claiming the Clinton campaign was involved in occult rituals—it would be tweeted by many bots, and humans, beguiled by the apparent popularity of the content, would retweet it.
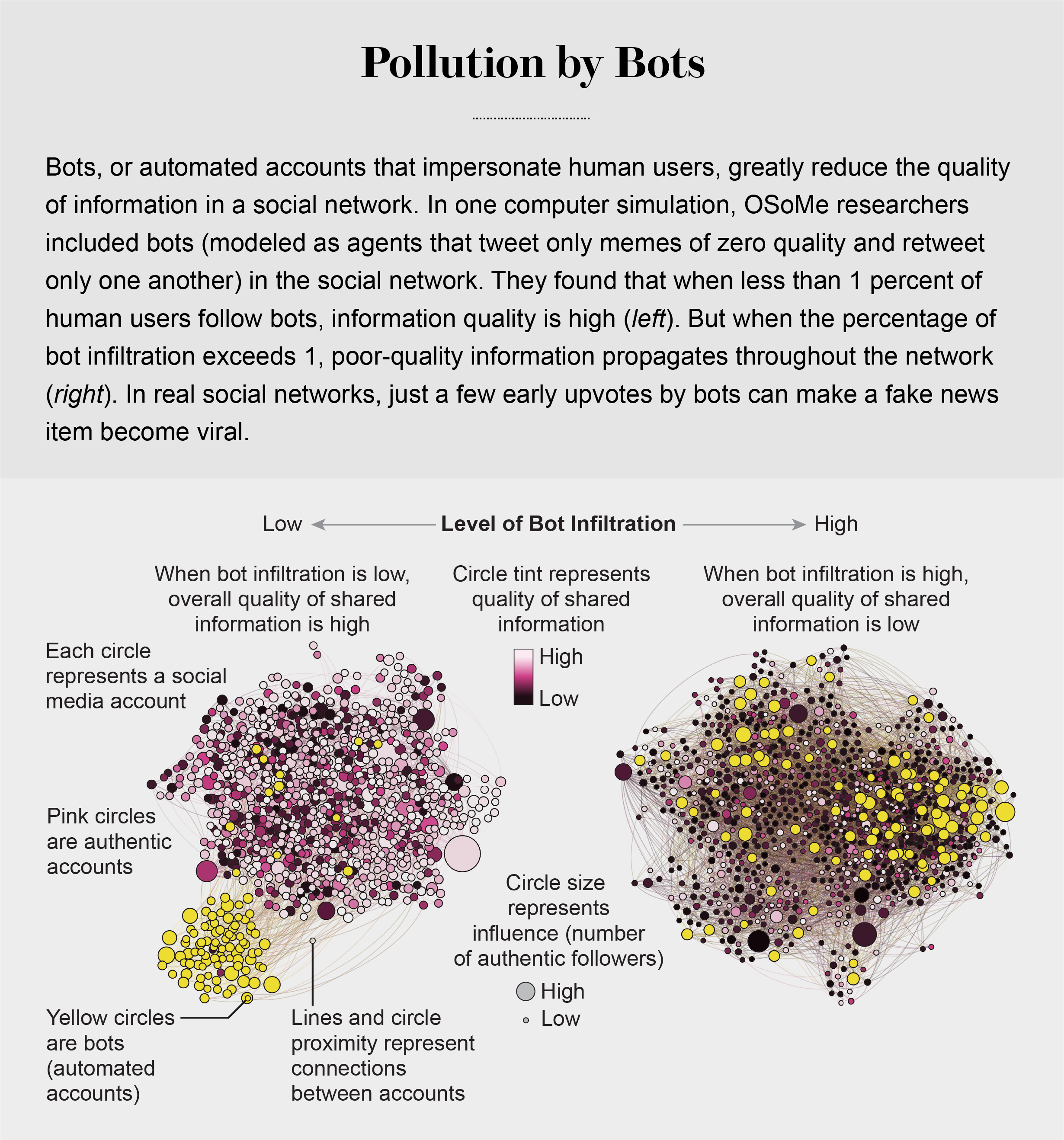
Bots also influence us by pretending to represent people from our in-group. A bot only has to follow, like and retweet someone in an online community to quickly infiltrate it. OSoMe researcher Xiaodan Lou developedanother modelin which some of the agents are bots that infiltrate a social network and share deceptively engaging low-quality content—think of clickbait. One parameter in the model describes the probability that an authentic agent will follow bots—which, for the purposes of this model, we define as agents that generate memes of zero quality and retweet only one another. Our simulations show that these bots can effectively suppress the entire ecosystem's information quality by infiltrating only a small fraction of the network. Bots can also accelerate the formation of echo chambers by suggesting other inauthentic accounts to be followed, a technique known as creating “follow trains.”
Some manipulators play both sides of a divide through separate fake news sites and bots, driving political polarization or monetization by ads. At OSoMe, we recentlyuncovered a network of inauthentic accountson Twitter that were all coordinated by the same entity. Some pretended to be pro-Trump supporters of the Make America Great Again campaign, whereas others posed as Trump “resisters”; all asked for political donations. Such operations amplify content that preys on confirmation biases and accelerate the formation of polarized echo chambers.
CURBING ONLINE MANIPULATION
Understanding our cognitive biases and how algorithms and bots exploit them allows us to better guard against manipulation. OSoMe has produced a number of tools to help people understand their own vulnerabilities, as well as the weaknesses of social media platforms. One is a mobile app calledFakeythat helps users learn how to spot misinformation. The game simulates a social media news feed, showing actual articles from low- and high-credibility sources. Users must decide what they can or should not share and what to fact-check. Analysis of data from Fakey confirms the prevalence of online social herding:users are more likely to share low-credibility articleswhen they believe that many other people have shared them.
Another program available to the public, calledHoaxy, shows how any extant meme spreads through Twitter. In this visualization, nodes represent actual Twitter accounts, and links depict how retweets, quotes, mentions and replies propagate the meme from account to account. Each node has a color representing its score from Botometer, which allows users to see the scale at which bots amplify misinformation. These tools have been used by investigative journalists to uncover the roots of misinformation campaigns, such as one pushing the “pizzagate” conspiracy in the U.S. They also helped to detectbot-driven voter-suppression effortsduring the 2018 U.S. midterm election. Manipulation is getting harder to spot, however, as machine-learning algorithms become better at emulating human behavior.
Apart from spreading fake news, misinformation campaigns can also divert attention from other, more serious problems. To combat such manipulation, we have recently developed a software tool calledBotSlayer. It extracts hashtags, links, accounts and other features that co-occur in tweets about topics a user wishes to study. For each entity, BotSlayer tracks the tweets, the accounts posting them and their bot scores to flag entities that are trending and probably being amplified by bots or coordinated accounts. The goal is to enable reporters, civil-society organizations and political candidates to spot and track inauthentic influence campaigns in real time.
These programmatic tools are important aids, but institutional changes are also necessary to curb the proliferation of fake news. Education can help, although it is unlikely to encompass all the topics on which people are misled. Some governments and social media platforms are also trying to clamp down on online manipulation and fake news. But who decides what is fake or manipulative and what is not? Information can come with warning labels such as the ones Facebook and Twitter have started providing, but can the people who apply those labels be trusted? The risk that such measures could deliberately or inadvertently suppress free speech, which is vital for robust democracies, is real. The dominance of social media platforms with global reach and close ties with governments further complicates the possibilities.
One of the best ideas may be to make it more difficult to create and share low-quality information. This could involve adding friction by forcing people to pay to share or receive information. Payment could be in the form of time, mental work such as puzzles, or microscopic fees for subscriptions or usage. Automated posting should be treated like advertising. Some platforms are already using friction in the form of CAPTCHAs and phone confirmation to access accounts. Twitter has placed limits on automated posting. These efforts could be expanded to gradually shift online sharing incentives toward information that is valuable to consumers.
Free communication is not free. By decreasing the cost of information, we have decreased its value and invited its adulteration. To restore the health of our information ecosystem, we must understand the vulnerabilities of our overwhelmed minds and how the economics of information can be leveraged to protect us from being misled.
As a Partner and Co-Founder of Predictiv and PredictivAsia, Jon specializes in management performance and organizational effectiveness for both domestic and international clients. He is an editor and author whose works include Invisible Advantage: How Intangilbles are Driving Business Performance. Learn more...




















0 comments:
Post a Comment